Writeup: FlareOn 2021: 007 - spel
1. TLDR

2. Dane wejściowe
Plik z zadaniem znajduje się tutaj. Hasło: flare.
Przedmiotem zadania jest plik spel.exe
3. Analiza wstępna
Po uruchomieniu zobaczyłem komunikat o błędzie:
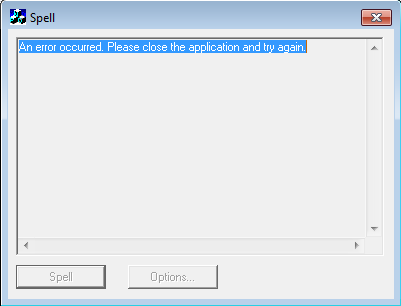
Czyżby z aplikacją było coś nie tak?
Myślałem że coś jest nie tak z setupem mojego środowiska. Może miałem problem z dźwiękiem? Brak dostępu do jakiegoś urządzenia? Nie ta wersja systemu? Podczas debuggowania aplikacji okazało się, że proces po zamknięciu okna dalej działa, hmmmm…..
W zdeasemblowanym kodzie widziałem dużo wywołań z klasy CWinApp świadczących o tym, że kod aplikacji zostały napisany z wykorzystaniem biblioteki Microsoft Foundation Class (MFC). Poniżej przykład listy funkcji z tej biblioteki użytych w aplikacji spel.exe:
Przejrzałem listę importów w poszukiwaniu wywołań:
CreateThread
CreateProcessInternalW
VirtualAlloc
VirtualProtect
W trakcie tej czynności zauważyłem nietypową (przynajmniej w mojej opinii) funkcję VirutalAllocExNuma
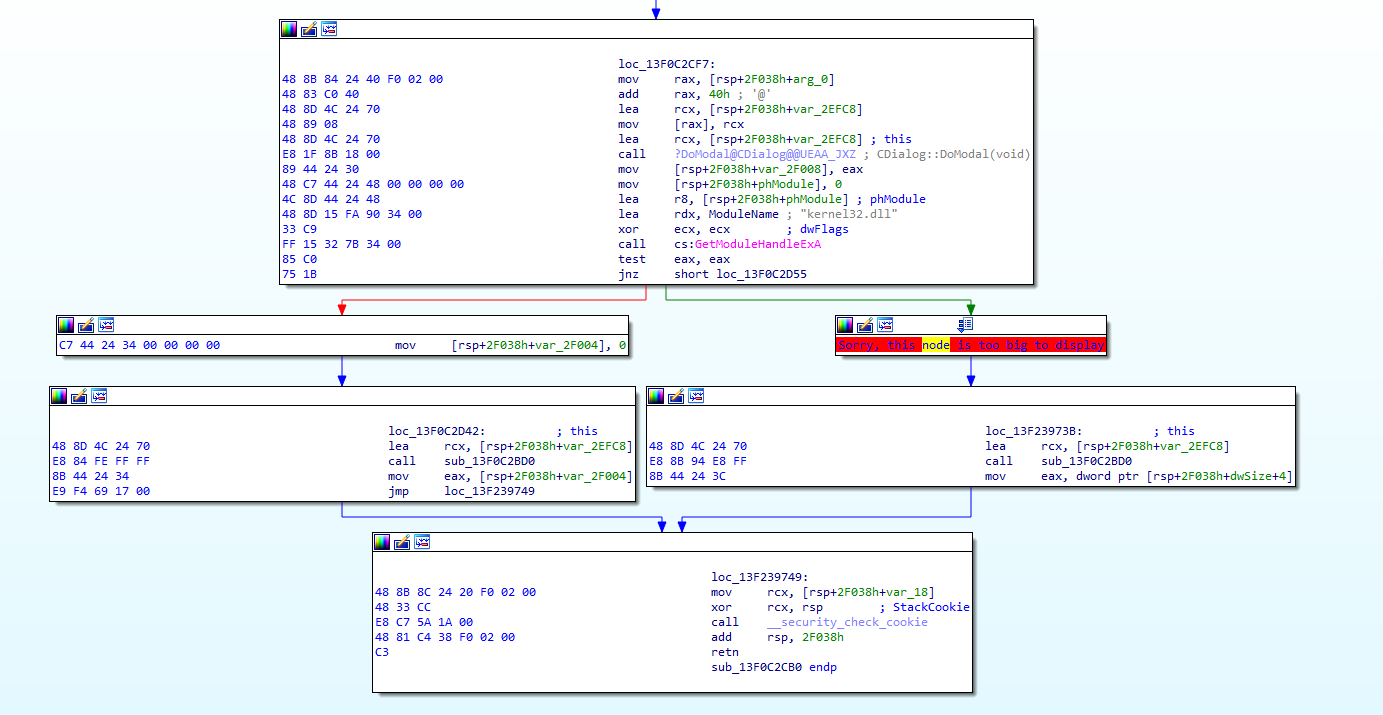
Próba zlokalizowania fragmentu kodu wywołującego tą funkcję (w widoku grafu kodu) zakończyła się niepowodzeniem:
Zlokalizowanie funkcji VirutalAllocExNuma w widoku listingu pozwoliło na ujawnienie interesującego fragmentu kodu. Moją uwagę zwrócił długi ciag rozkazów mov układający dane w pamięci, który został zakończony ułożeniem literału “flare”, a następnie alokacja pamięci, jej skopiowanie oraz wykonanie danych jako kod:
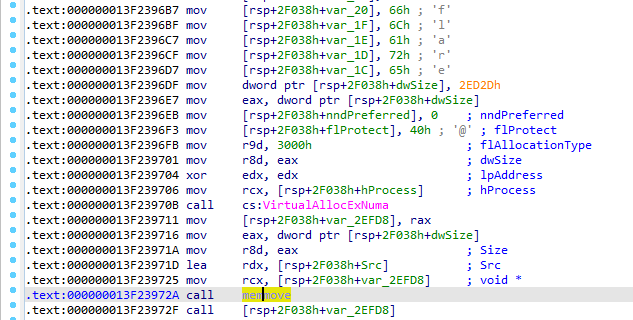
4. Analiza szczegółowa
Używając x64dbg wykonałem kod do breakpointa ustawionego na VirutalAllocExNuma, który zaalokował adres 0x260000, i po wywołaniu funkcji memmove, zobaczyłem pod tym adresem potencjalny shellcode. Było chyba dobrze, pierwszy rozkaz to call (E8):
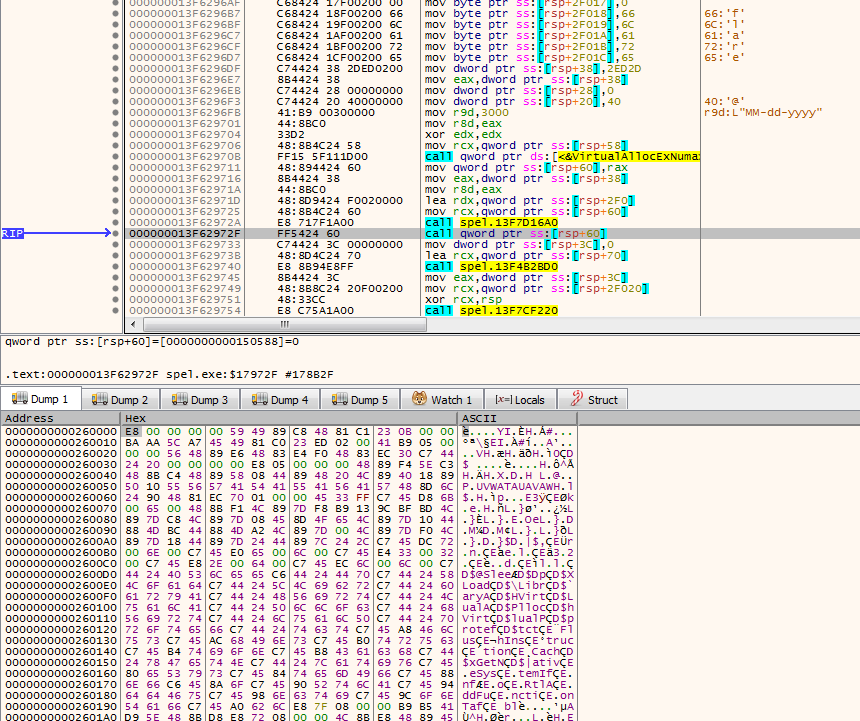
Używając Process Hackera zrzuciłem cały obszar pamięci:
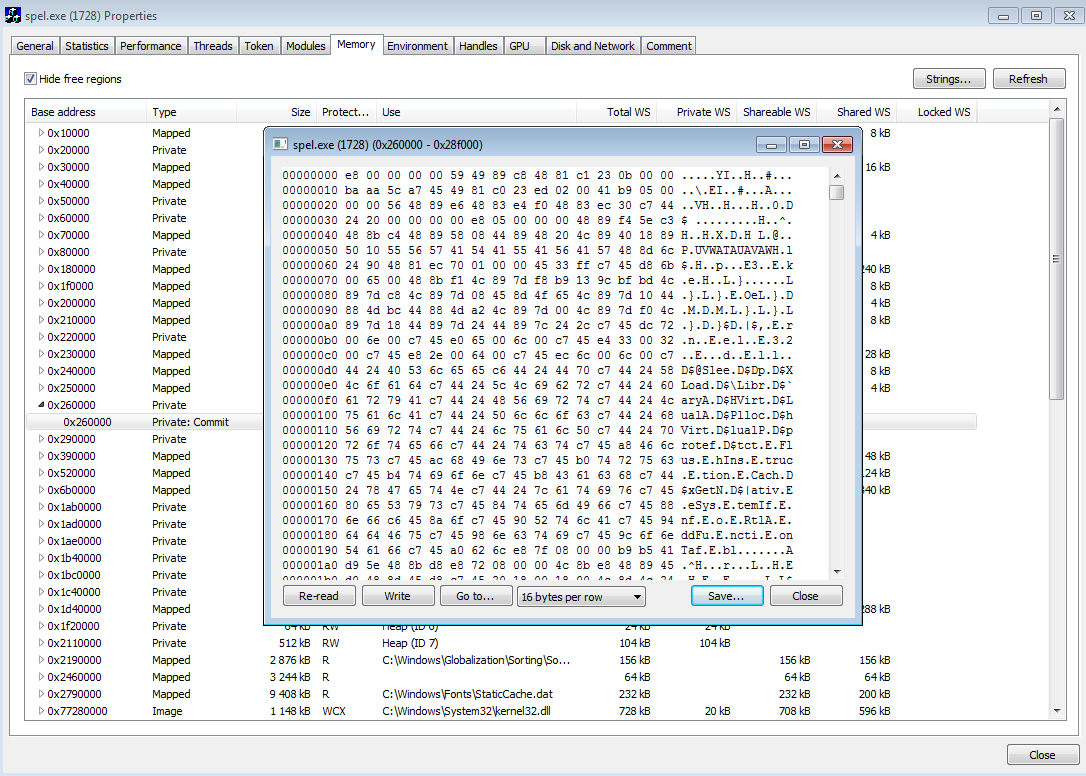
W celu ograniczenia rozmiaru dumpu do fragmentu, który miał jakiekolwiek znaczenie dla shellcodu, otworzyłem zrzut pamięci w HxD. Szybko zauważyłem że tuż obok shellcodu znajduje się plik PE, który wyodrębiłem i bez analizy shellcodu założyłem, że jest on przez niego ładowany.
Ładowany plik okazał się być plikiem DLL:
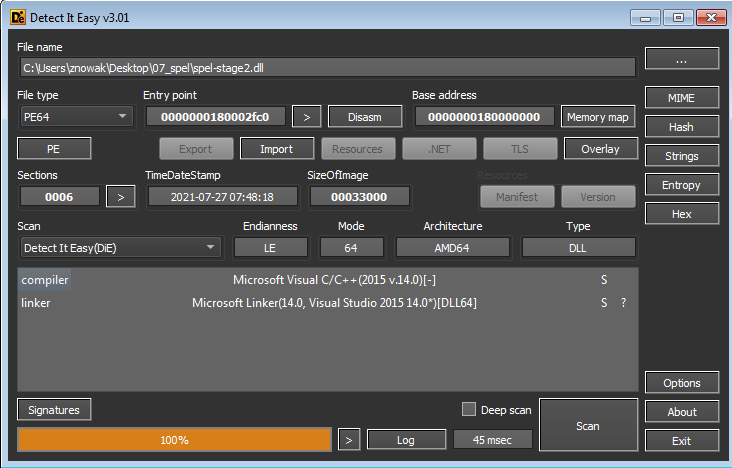
Po załadowaniu dll do narzędzia IDA, zauwayżyłem dwie ciekawe rzeczy:
- DLL nie miała żadnych exportów oprócz DllEntryPoint.
- Funkcja DLL używała bardzo długiej tablicy bajtów, którą przekazywała do nienzanej mi funkcji. Bardzo długiej tablicy, która była kolejnym plikiem PE.
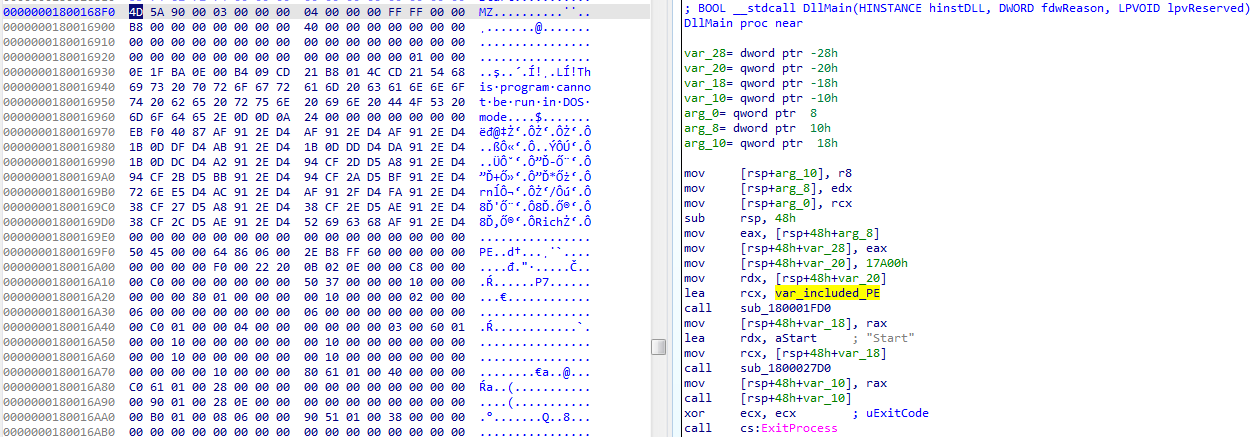
Wyodrębniłem zatem zagnieżdżony plik:
> emit spel-stage2.dll | carve-pe > spel-stage3.dll
Kolejny, ładowany plik okazał się być plikiem DLL:
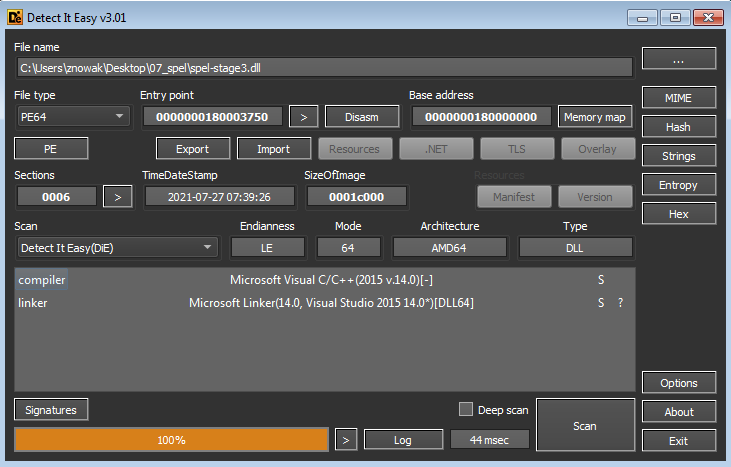
Analiza statyczna kodu doprowadziła mnie do kilku spostrzeżeń:
- Funkcje są dynamicznie importowane
- Nazwy importowanych funkcji i bibliotek są zacieminone
- Wszystkie stringi są zaciemnione: zaszyfrowane xorem, którego klucz każdorazowo znajdował się kilka instrukcji po załadowaniu szyfrogramu do pamięci. Na rysnku poniżej zaznaczono odpowiedno ładowanie szyfrogramu oraz odszyfrowanie:
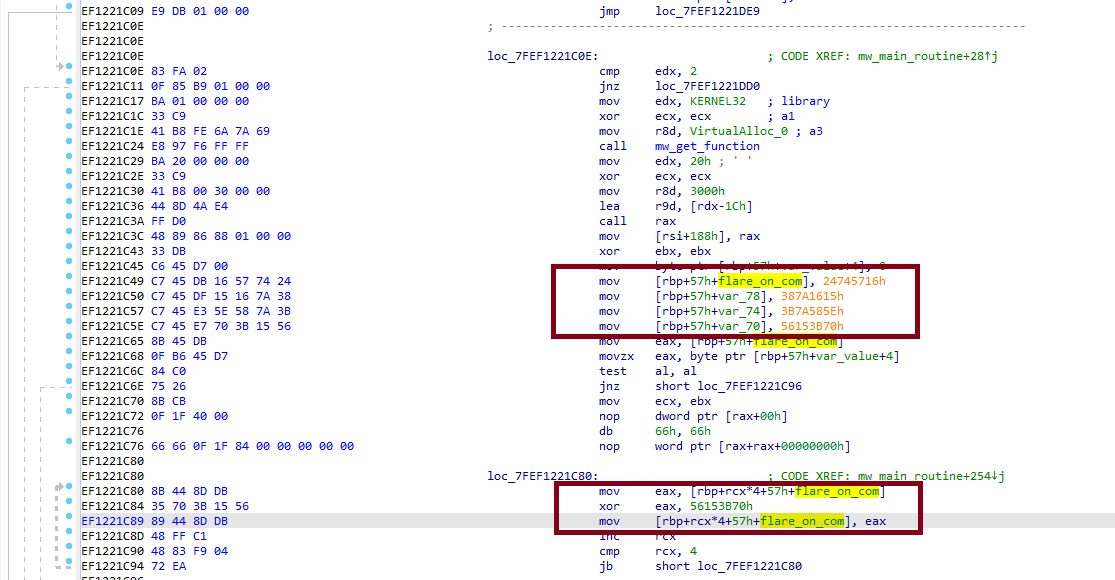
5. Deobfuskacja
Nazwy bibliotek były mapowane z liczba całkowitych, skonstruowanie typu wyliczeniowego ułatwiło analizę takiej metody zaciemiania kodu:
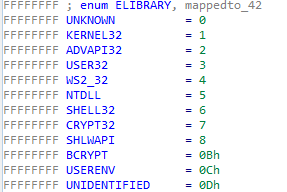
Sama obfuskacja nazw ładowanych funkcji nie stanowiła problemu, dzięki skorzystaniu z bazy HashDb oraz wtyczki do środowiska IDA
Obfuskację stringów rozwiązałem poniższym skryptem:
import idautils
import idc
import ida_ua
import ida_bytes
import idaapi
import struct
import malduck
def get_ciphertext(ea):
input = list()
for x in range(0,15):
if ida_ua.ua_mnem(ea) == 'mov' and idc.get_numbered_type_name(idc.get_operand_type(ea, 1))=='DWORD':
value = idc.get_operand_value(ea, 1)
if value!=0:
value = struct.pack("<I", value)
input.append(value)
else:
break
ea = ida_bytes.next_head(ea, ida_ida.cvar.inf.max_ea)
return (ea,bytes().join(input))
def get_key(ea):
while ida_ua.ua_mnem(ea) != 'xor' or idc.get_numbered_type_name(idc.get_operand_type(ea, 1))!='DWORD':
ea = ida_bytes.next_head(ea, ida_ida.cvar.inf.max_ea)
key = idc.get_operand_value(ea, 1)
key = struct.pack("<I", key)
return (ea,bytes(key))
ea = idc.here()
ea, ciphertext = get_ciphertext(ea)
ea, key = get_key(ea)
plaintext = malduck.xor(key, ciphertext)
plaintext_utf8 = plaintext.decode("UTF-8")
plaintext_utf16 = plaintext.decode("UTF-16")
print(f"key:{key}")
print(f"ciphertext:{ciphertext}")
print(f"plaintext_utf8:{plaintext_utf8}")
print(f"plaintext UTF-16:{plaintext_utf16}")
Dalsza analiza kodu programu pozwoliła zauważyc, że program korzystał z biblioteki bcrypt oraz dostarczanej przez niego implementacji algorytmu AES-128. W ten sposób ładował i odszyfrywował fragment jeden z resource’ów o id 128:
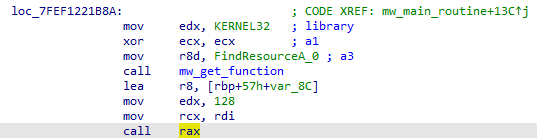
6. Analiza payloadu
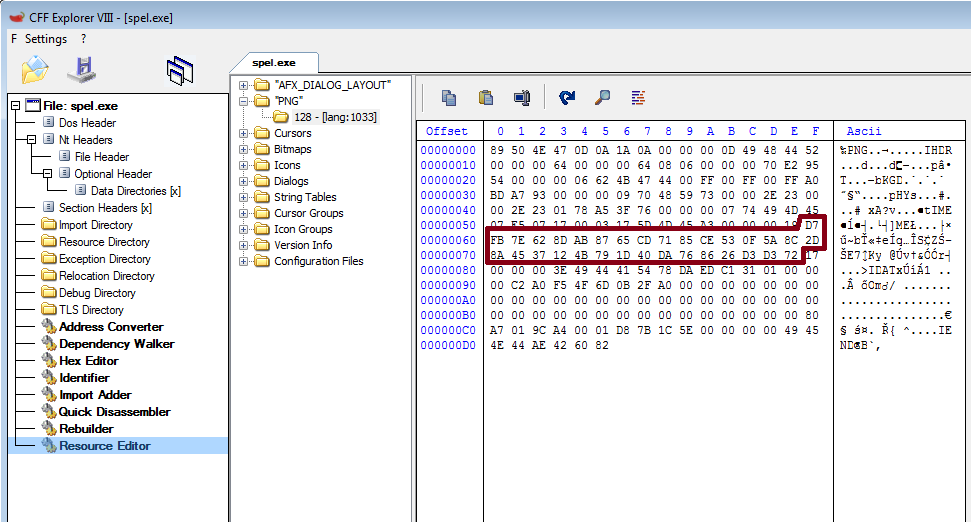
Zawartość tego resource’a odzyskałem narzędziem CFF Explorer, na czerwono zaznaczono faktyczny szyfrogram:
Wykorzystanym kluczem był jeden ze stringów:
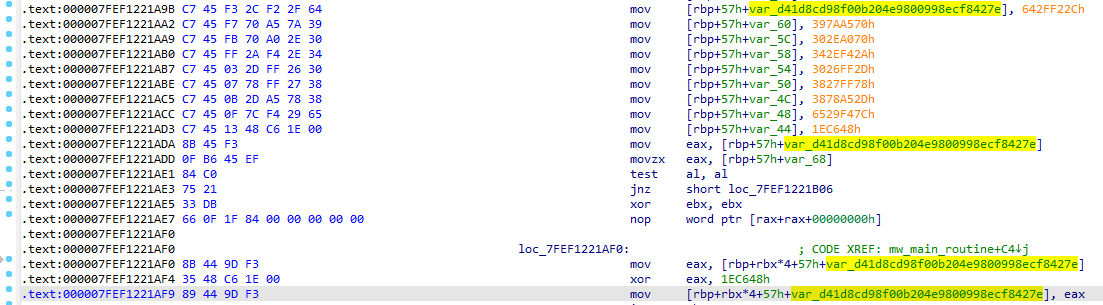
IV stanowił ciąg: 80808080808080808080808080808080
Odszyforwałem zatem szyfrogram korzystając z Binary Refinery
$ emit 80808080808080808080808080808080D7FB7E628DAB8765CD7185CE530F5A8C2D8A4537124B791D40DA768626D3D372 | hex | aes --mode cbc -i cut::16 d41d8cd98f00b204e9800998ecf8427e
l3rlcps_7r_vb33eehskc3
Po odszyfrowaniu ciąg był ponownie zaciemnany xorem oraz zmieniana była kolejność znaków:

7. Odczytanie flagi
Wystarczyło zignorować szyfr strumieniowy oraz odczytać prawidłową kolejność znaków:
p = "l3rlcps_7r_vb33eehskc3"
indexes = [12,13,6,8,7,6,5,1,0,3,4,17,15,20,19,21,2,10,16,11,14,2]
t=[]
for i in indexes:
t.append(p[i])
t = ''.join(t)
print(t)
Flaga:
b3s7_sp3llcheck3r_ev3r@flare-on.com